隨著人工智能技術的飛速發展,AI大模型(如GPT、BERT等)已成為推動創新的核心驅動力。AI大模型的網絡搭建涉及復雜的硬件、軟件和網絡架構設計,而相應的網絡技術服務則是確保模型高效運行和拓展的關鍵。本文將系統介紹AI大模型網絡搭建的步驟,并探討網絡技術服務的核心內容。
一、AI大模型網絡搭建的關鍵步驟
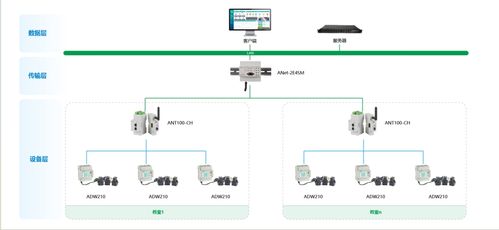
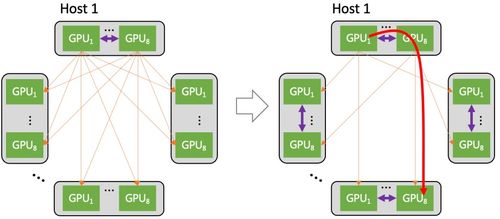
- 硬件基礎設施規劃:AI大模型需要強大的計算資源,通常采用GPU集群(如NVIDIA A100或H100)來支持訓練和推理。網絡搭建首先需設計高速互聯架構,例如使用InfiniBand或RoCE(RDMA over Converged Ethernet)技術,以減少通信延遲并提升數據傳輸效率。需確保充足的存儲系統,如分布式文件系統或對象存儲,以處理海量數據集和模型參數。
- 軟件環境配置:搭建網絡需部署專用軟件棧,包括深度學習框架(如TensorFlow、PyTorch)和分布式訓練工具(如Horovod或NCCL)。容器化技術(如Docker和Kubernetes)常用于管理資源,確保模型可伸縮部署。需設置監控和日志系統,實時跟蹤網絡性能和模型狀態。
- 網絡架構設計:對于大規模模型,網絡拓撲結構至關重要。常見的架構包括星型、環型或混合拓撲,以優化節點間通信。安全措施如防火墻、VPN和加密協議必須集成,防止數據泄露和攻擊。網絡帶寬和延遲需通過負載均衡和流量管理工具進行優化,確保訓練過程的穩定性。
- 數據管道與預處理:搭建網絡時,需構建高效的數據管道,支持數據的采集、清洗和預處理。這可能涉及與云服務(如AWS或Azure)集成,實現數據流的無縫對接。數據隱私和合規性需通過匿名化或聯邦學習技術來處理。
二、網絡技術服務在AI大模型中的應用
網絡技術服務是AI大模型生命周期中的支撐環節,主要包括:
- 部署與運維服務:提供模型的云端或本地部署,包括自動化腳本、持續集成/持續部署(CI/CD)流程,以及7x24監控服務,確保高可用性和快速故障恢復。
- 性能優化服務:通過網絡分析工具(如Wireshark或Prometheus)診斷瓶頸,優化數據傳輸和計算負載。這可能包括調整網絡參數、實施緩存策略或采用邊緣計算以減少延遲。
- 安全與合規服務:提供端到端加密、訪問控制和漏洞掃描,確保模型和數據在網絡傳輸中的安全。協助滿足GDPR、HIPAA等法規要求。
- 可擴展性支持:隨著模型規模擴大,網絡技術服務可幫助擴展集群規模,采用微服務架構或serverless計算,實現彈性資源分配。
三、實踐建議與未來展望
在搭建AI大模型網絡時,建議從小規模原型開始,逐步測試網絡性能。與專業網絡服務提供商合作可加速部署,例如利用云計算平臺的托管服務(如Google AI Platform或Azure Machine Learning)。隨著5G和6G技術的發展,AI大模型網絡將更加高效,網絡技術服務也將融入更多AI驅動的自動化工具,實現智能運維。
AI大模型網絡搭建是一個多學科集成的過程,而網絡技術服務則保障了其可靠性和可擴展性。通過合理規劃和持續優化,企業和研究機構可以充分發揮AI大模型的潛力,推動數字化轉型。